Transforming Written Lyrics into Full Musical Compositions via Machine Learning
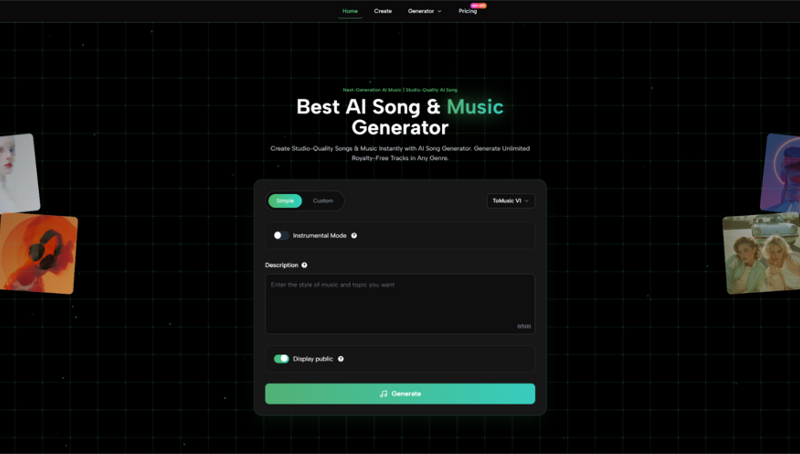
Songwriters and poets frequently encounter a “writer’s block” of a different kind: they have the words, but the melody remains elusive. Staring at a page of lyrics without a musical accompaniment can halt the creative process entirely, leaving potential songs unfinished. By utilizing an AI Music Generator, lyricists can instantly hear their words performed in various styles, serving as a powerful co-pilot for composition and arrangement.
Analyzing the Lyric to Audio Engine
The core value proposition of these platforms lies in their ability to align phonemes (speech sounds) with generated musical notes. This “Lyrics to Music” capability is distinct from simple background music generation because it requires the AI to understand rhythm, rhyme schemes, and emotional inflection.
Feature Breakdown for Songwriters
The table below outlines how specific features of AI music tools cater to the songwriting workflow compared to standard music production software (DAWs).
| Capability | Standard DAW (Logic/Ableton) | AI Music Generator |
| Melody Creation | Manual (Requires midi/recording) | Automated (AI suggests melody) |
| Lyric Alignment | Manual (Recording vocals) | Automated (Text-to-speech singing) |
| Arrangement | Manual (Building layers) | Instant (Full backing track) |
| Skill Requirement | High (Music theory/Audio eng) | Low (Text input only) |
| Iteration Speed | Slow (Hours/Days) | Fast (Minutes) |
Practical Application for Songwriters
Based on the operational flow of ToMusic, the application of this technology follows a clear, linear path designed to move from text to audio quickly.
Inputting Custom Lyrics and Structure
The user begins by pasting their written lyrics into the interface. To get the best results, it helps to structure the text clearly, denoting sections like [Verse] and [Chorus]. This cues the model to alter the energy and melody dynamics between sections, simulating a traditional song structure.
Selecting the Musical Style and Emotion
The emotional context of the lyrics must match the musical backing.
- Genre Selection: A sombre lyric might require a “Ballad” or “Acoustic” setting, while an upbeat track needs “Pop” or “Dance.”
- Voice Selection: Some platforms allow users to select the “singer’s” voice type (e.g., male, female, gritty, clean) to better fit the narrative of the song.
Reviewing and Downloading the Composition
Upon generation, the system produces a complete track with the lyrics sung by an AI voice. Users can listen to the output and, if necessary, download separate “stems” (isolated vocal and instrumental tracks). This is particularly useful for musicians who might want to keep the AI-generated melody but re-record the vocals themselves.
Limitations in Vocal Synthesis Quality
It is important to address the current limitations of this technology. While the instrumental generation is often robust, the “singing” voice can occasionally sound over-processed or exhibit “autotune” artifacts. In my testing, the emotional delivery does not yet match a professional human vocalist’s nuance. However, as a demo tool or a source of melodic inspiration, it provides immense value. External studies on generative media indicate that while we are approaching high-fidelity voice synthesis, the “human touch” in musical phrasing is still a developing frontier.
The core value proposition of these platforms lies in their ability to align phonemes (speech sounds) with generated musical notes. This “Lyrics to Music” capability is distinct from simple background music generation because it requires the AI to understand rhythm, rhyme schemes, and emotional inflection.
Feature Breakdown for Songwriters
The table below outlines how specific features of AI music tools cater to the songwriting workflow compared to standard music production software (DAWs).
| Capability | Standard DAW (Logic/Ableton) | AI Music Generator |
| Melody Creation | Manual (Requires midi/recording) | Automated (AI suggests melody) |
| Lyric Alignment | Manual (Recording vocals) | Automated (Text-to-speech singing) |
| Arrangement | Manual (Building layers) | Instant (Full backing track) |
| Skill Requirement | High (Music theory/Audio eng) | Low (Text input only) |
| Iteration Speed | Slow (Hours/Days) | Fast (Minutes) |
Practical Application for Songwriters
Based on the operational flow of ToMusic, the application of this technology follows a clear, linear path designed to move from text to audio quickly.
Inputting Custom Lyrics and Structure
The user begins by pasting their written lyrics into the interface. To get the best results, it helps to structure the text clearly, denoting sections like [Verse] and [Chorus]. This cues the model to alter the energy and melody dynamics between sections, simulating a traditional song structure.
Selecting the Musical Style and Emotion
The emotional context of the lyrics must match the musical backing.
- Genre Selection: A sombre lyric might require a “Ballad” or “Acoustic” setting, while an upbeat track needs “Pop” or “Dance.”
- Voice Selection: Some platforms allow users to select the “singer’s” voice type (e.g., male, female, gritty, clean) to better fit the narrative of the song.
Reviewing and Downloading the Composition
Upon generation, the system produces a complete track with the lyrics sung by an AI voice. Users can listen to the output and, if necessary, download separate “stems” (isolated vocal and instrumental tracks). This is particularly useful for musicians who might want to keep the AI-generated melody but re-record the vocals themselves.
Limitations in Vocal Synthesis Quality
It is important to address the current limitations of this technology. While the instrumental generation is often robust, the “singing” voice can occasionally sound over-processed or exhibit “autotune” artifacts. In my testing, the emotional delivery does not yet match a professional human vocalist’s nuance. However, as a demo tool or a source of melodic inspiration, it provides immense value. External studies on generative media indicate that while we are approaching high-fidelity voice synthesis, the “human touch” in musical phrasing is still a developing frontier.