How to Engineering High Fidelity Motion Through Advanced Diffusion Architecture with Seedance 2.0
The rapid evolution of generative media is driven by a fundamental shift in underlying neural architectures, moving from simple frame interpolation to complex physics simulation. Early attempts at AI video synthesis often resulted in the “uncanny valley” effect, where motion felt weightless and textures appeared to dissolve between frames. This lack of physical grounding limited the technology’s application to abstract art rather than realistic simulation. However, the integration of Diffusion Transformer models is rewriting these rules. By analyzing the structural capabilities of Seedance 2.0, we can observe a significant leap in how machines interpret and render temporal data. This progression is not merely about higher pixel counts; it is about the accurate modeling of light, gravity, and object permanence over time, bridging the gap between digital hallucination and photorealistic rendering.
For technical directors and visual effects artists, the distinction lies in the details. A standard model might generate a walking figure, but a sophisticated architecture ensures the footsteps land with weight and the fabric of the clothing reacts naturally to the movement. The capability to process high-resolution data without losing temporal coherence suggests that we are entering a phase where AI can serve as a reliable engine for pre-visualization and high-end content creation. This shift is powered by specific architectural choices that prioritize the separation of spatial and temporal attention, allowing for a level of control that previous generations of GAN-based models could not achieve.
Deconstructing The Role Of VAE And Diffusion Transformers
The core engine driving this enhanced fidelity is the combination of Variational Autoencoders (VAE) and Diffusion Transformer architectures. Unlike traditional convolutional networks that often blur fine details during upscaling, this hybrid approach allows for the preservation of intricate textures at a granular level. The VAE compresses visual information into a latent space where it can be manipulated efficiently, while the Diffusion Transformer reconstructs this data into coherent video sequences.
Achieving Broadcast Quality Through Latent Space Optimization
The practical result of this architecture is the ability to output native 1080p resolution. In my analysis of the technical specifications, the model does not simply “guess” the pixels between keyframes; it understands the semantic structure of the image. This is crucial for maintaining sharpness in complex scenes involving water, fire, or detailed character close-ups. By operating in a high-dimensional latent space, the system can generate 5 to 12 seconds of content where the visual fidelity at the end of the clip matches the quality of the start.
Leveraging Qwen2.5 For Precise Prompt Interpretation
Visual generation is only as good as the model’s understanding of the input. The integration of the Qwen2.5 language model serves as the cognitive bridge between human intent and machine execution. This linguistic component allows the system to parse complex, multi-layered prompts that describe not just the subject, but the camera lens, the lighting temperature, and the specific mood. It translates abstract “director-style” instructions into mathematical vectors that guide the diffusion process, ensuring that a request for “cinematic lighting” results in physically accurate shadow falloff rather than just a darkened image.
Navigating The Technical Workflow From Input To Rendering

To utilize these architectural capabilities effectively, the user interaction model has been streamlined into a linear process. This workflow abstracts the complex backend calculations into a user-friendly interface, allowing creators to focus on the aesthetic outcome rather than the computational parameters.
Step One Initializing The Generation With Multimodal Inputs
The procedure begins with the definition of the source material. Users input a descriptive text prompt or upload a reference image. This stage leverages the model’s multimodal understanding to establish the visual baseline. The system analyzes the input for semantic cues regarding the environment and the subject’s physical properties. Providing a high-quality reference image at this stage significantly reduces the variance in the output, locking in specific character traits or stylistic elements before the temporal generation begins.
Step Two Configuring Spatial And Temporal Output Settings
Following the creative input, the user must define the structural constraints of the video. This involves selecting the resolution (up to 1080p), the aspect ratio, and the duration. The choice of aspect ratio—whether 16:9, 9:16, or 21:9—instructs the model on how to frame the subject within the latent space. The duration setting determines the complexity of the temporal attention mechanism; generating a 60-second clip requires a different computational approach than a 5-second loop, often involving the stitching of multiple coherent segments.
Step Three Executing The Diffusion Process On Specialized Hardware
Once the command is issued, the model initiates the generation phase. This process runs on high-performance hardware, such as the NVIDIA L20, to handle the massive computational load of the Diffusion Transformer. During this phase, the system iteratively denoises the latent representation, gradually revealing the video frames while simultaneously synthesizing the synchronized audio track. The speed of this process—approximately 41 seconds for a 5-second high-definition clip—demonstrates the efficiency of the underlying architecture relative to the complexity of the task.
Step Four Finalizing The Asset For Professional Application
The conclusion of the workflow is the export of the rendered file. The system produces a watermark-free MP4, ensuring the content is ready for professional integration. At this stage, the video has been fully reconstructed from the latent space into a viewable format, with all audio-visual synchronization baked into the single file. This allows for immediate review and deployment across broadcasting or digital streaming platforms without the need for intermediate transcoding.
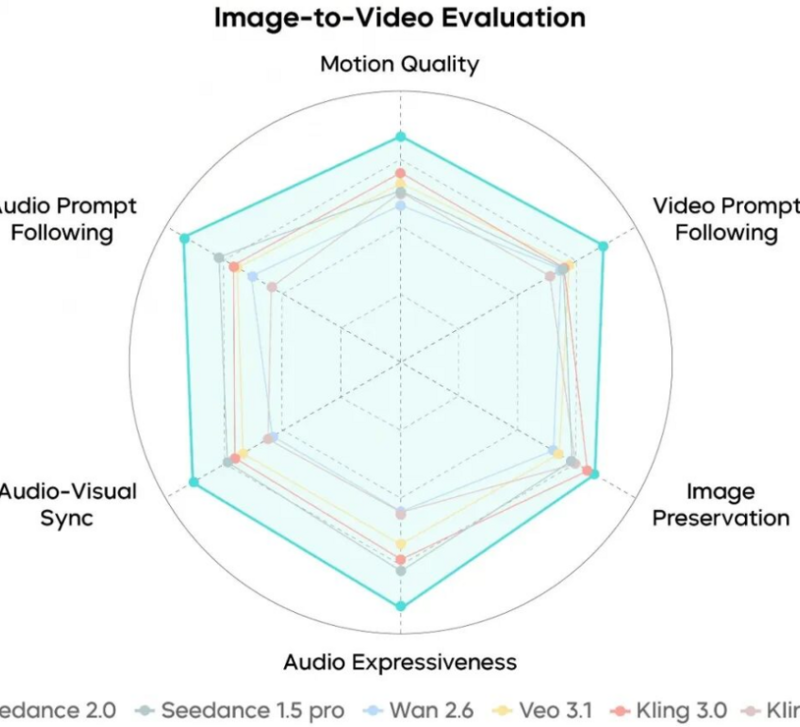
Benchmarking Architectural Capabilities Against Market Standards
To appreciate the advancements in this specific model, it is necessary to compare its technical metrics with the broader field of AI video generation. The following table illustrates the differences in architecture, resolution, and narrative handling.
| Technical Metric | Conventional Diffusion Models | Seedance 2.0 Architecture |
| Core Architecture | Standard U-Net / GANs | VAE + Diffusion Transformer |
| Language Understanding | Basic CLIP integration | Fine-tuned Qwen2.5 LLM |
| Max Native Resolution | 512p / 720p (Upscaled) | Native 1080p High Definition |
| Temporal Coherence | Frequent morphing/flickering | High stability via temporal attention |
| Audio Synthesis | Separate or non-existent | Integrated multimodal generation |
| Render Efficiency | Variable, often minutes per second | Approx. 41s for 5s (HD) |
Identifying The Computational Boundaries Of Current Technology
Despite the sophisticated architecture, current generative models operate within distinct physical and computational limits. The reliance on heavy GPU acceleration highlights that this is not yet a real-time rendering solution; the 41-second processing time for a short clip indicates a significant latency for interactive applications. Furthermore, while the Qwen2.5 model improves prompt adherence, it acts as a literal interpreter. It cannot infer creative nuance that isn’t explicitly stated, meaning the output quality is strictly bound by the descriptive capability of the user.
Additionally, the “native” generation limit of 5-12 seconds reflects the current memory constraints of keeping a coherent temporal state in VAEs. Extending this to 60 seconds involves intelligent sequencing rather than a single continuous generation pass, which can introduce subtle shifts in continuity if the prompt is not robust. Recognizing these architectural boundaries is essential for professionals who wish to integrate this tool into a production pipeline, ensuring they use it for tasks where its strengths—resolution and texture—outweigh its temporal limitations.